Izviniavam se za nesuotvetstviiata v pokazanite znatsi.
SHTe se pogrizha da redaktiram statiiata i tam, kudeto ima nesuotvetstviia shte postavia kartinki, za da sum siguren, che shte vidite, tova, koeto triabva da vidite
Referentni vruzki kum statiiata:
http://berov.data.bg/Cyr_and_charsets/tools/README.htm
Zabelezhka:
!!! Tezi dokumenti niama da se zarediat pravilno, zashtoto survurut (data.bg) izprashta hedur charset=windows-1251, a dokumentite sa kodirani v utf-8.
Za da gi vidite kakto triabva v brauzura si, izpolzvaite menyuto View>Encoding>utf-8
[NIKOGA NE PUBLIKUVANA STATIQ]
Rabotno zaglavie:
Kirilitsata i kodovite tablitsi
(izpolzvane na razlichni kodovi tablitsi v Internet)
Krasimir Berov
Uvod
Za potrebiteli
(kak da chetem i izprashtame elektronnata si poshta, izpolzvaiki kirilitsa)
Goliama chast ot nas — potrebitelite imat poshtenski kutii na niakoi ot bezplatnite poshtenski survuri po sveta. Ot niakolko godini nasam se poiaviha i mnogo bulgarski survuri, obsluzhvashti potrebitelski poshtenski kutii — plateni i bezplatni. Makar i zapoznati s fakta, che mozhe da se polzva kirilitsa, mnogo ot nas produzhavat da polzvat “po-sigurnata” “internetitsa”, kakto ia beshe narekul Martin Karbovski v edna svoia statiia. Za suzhalenie ot neia ne stavashe iasno zashto se sluchva taka. E, po-natatuk shte obiasnim, a sega samo shte pokazhem kak da polzvame sistemata ot simvoli na Svetite Bratia i uchenika im sv. Kliment Ohridski.
TSeliiat problem se koreni vuv fakta, che pochti vsiaka strana, izpolzvashta simvolite na sv. Kliment Ohridski (zashtoto toi suzdava kirilitsata), ima svoia sistema za predstaviane na tezi znatsi vurhu standartniia izhod — ekrana. Osven samite vutredurzhavni organi po standartizatsiia ima i vunshni faktori kato MICROSOFT CORPORATION, W3C-World Wide Web Consortium, ISO-International Standards Organization, Unicode Consortium, koito predlagat svoi sistemi i nalagat izpolzvaneto na opredeleni shemi za transformirane na chisla v simvoli vurhu ekrana.
Nas — krainite potrebiteli ne ni interesuva nishto ot tova, do momenta, v koito ne otvorim niakoi dokument v MS Word (ili prosto v poshtenskata si kutiia v brauzura) i se okazhe, che toi e izpustren s kvadratcheta ili stranni bukvi s udareniia.
Eto nai-izpolzvanite t.nar kodovi tablitsi za predstaviane na kirilski simvoli.
- windows-1251 ili cp1251
- koi-8r
- koi-8u
- cp866
- iso-8859-5
- utf-8
Za da izpolzvate kirilitsa, kogato izprashtate ili poluchavate elektronna poshta:
A: Internet Explorer
Ako ne ste nastroili brauzura si predvaritelno da priema opredeleni kodovi tablitsi ili puk ochakvate pismo kodirano s opredelena kodova tablitsa, ot menyuto View izberete Encoding i ot tam izberete kodovata tablitsa, koiato eventualno e izpolzvana.
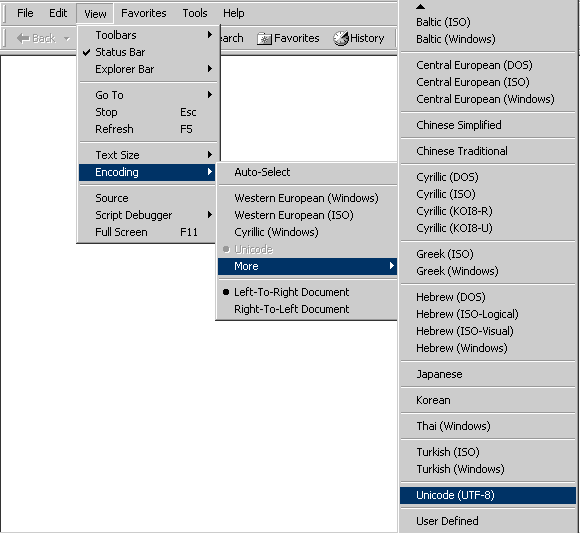
fig.1 Izpolzvane na razlichni kodovi tablitsi v Internet Explorer
B: Mozilla 1/Netscape 6 i sledvashti versii
Tuk menyutata sa podobni.
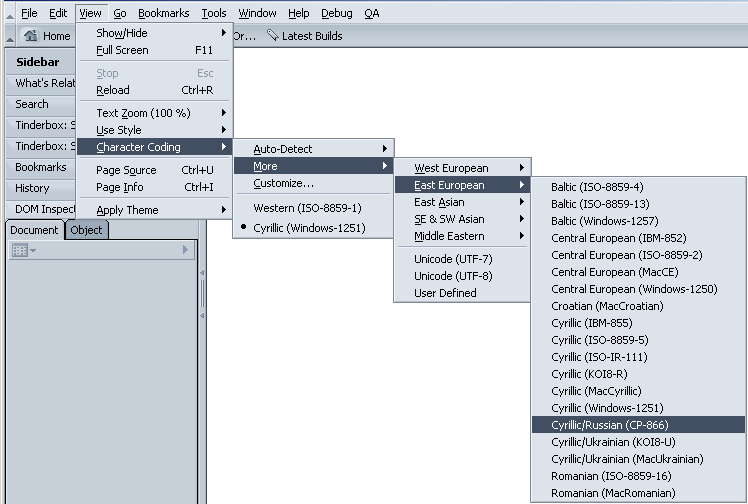 fig.2 Izpolzvane na razlichni kodovi tablitsi v Mozilla /Netscape
fig.2 Izpolzvane na razlichni kodovi tablitsi v Mozilla /Netscape
Tezi umeniia mozheshe i da ne sa vi neobhodimi, ako saitut, hostvasht vashata poshtenska kutiia, razpoznavashe ezika i kodovata tablitsa, koiato polzva vashiiat brauzur po podrazbirane. Malko saitove v mrezhata se grizhat za tova. Edin ot tiah e http://www.google.com. Toi se zarezhda napravo na kirilitsa i mozhete da tursite, izpolzvaiki bulgarski bukvi. I kirilitsata ne e nishto. Kakvo shte kazhete za iaponskite ili kitaiskite ideografii? Ostavate vpechatleni, nali?
Kogato reshite da si pishete s niakoi priiatel, zaminal v chuzhbina, prosto se ugovorete koia kodova tablitsa shte polzvate. Taka niama da imate problemi s kirilitsata. Izberete si niakakuv poddurzhan ot negovata i ot vashata operatsionna sistema shrift, i ste gotovi.
V sluchai, che ste ot horata, koito obichat da si plashtat, vie nai-veroiatno imate poshtenska kutiia na niakoi ot platenite survuri i polzvate programa kato Outlook Express. Po printsip nastroikite za polzvanata kodova tablitsa ot vashata operatsionna sistema sa napraveni oshte po vreme na neinoto instalirane. Tezi nastroiki se naslediavat ot povecheto prilozheniia, raboteshti na kompyutura vi v posledstvie. Kogato rabotite pod Windows, sistemata ne vi dava osobeni obiasneniia za kodovata tablitsa, koiato shte polzva. Tia sama reshava, che naprimer shtom se namirate v Bulgariia shte polzvate windows-1251. Neznaino zashto obache Outlook Express reshava da polzva koi-8r po podrazbirane.
Vizhte kak mozhete da izpratite pismo (Rich Text-HTML), izpolzvashto opredelena kodova tablitsa.
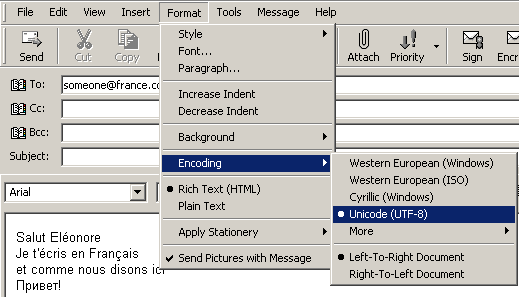
fig.3 Izpolzvane na utf-8 v Outlook Express
Vizhdate, che ne prosto e vuzmozhno da polzvate kirilitsa, no e vuzmozhno da polzvate viakakvi ezitsi v edin i susht dokument. Kak se sluchva tova, shte obiasnim po-natatuk.
I otnovo shte dam primer s izpolzvane na nai-lansiranata mezhdunarodna kodova tablitsa, tozi put s Mozilla Composer. Predvaritelno se izviniavam na vladeeshtite Qponski ezik. Edinstvenoto, koeto znam za vuvedenite ot men simvoli, e che sa Kanji, kakvoto i da oznachava tova. Razbira se, za da mozhete da vuzproizvedete tezi znatsi vi e neobhodim shrift, koito da gi sudurzha v sebe si.

fig.4 Izpolzvane na utf-8 v Mozilla Composer
Mozilla po printsip dava malko poveche informatsiia na potrebitelite za imenata na kodovite tablitsi.
Kato potrebiteli, koito iskat prosto da si svurshat rabota, naistina niamate nuzhda ot poveche. No dori ako vi e samo lyubopitno, kak rabotiat tezi abstraktni shemi, preminete kum sledvashtata chast.
Znatsi, kodovi tablitsi, repertoari, shriftove
(osnovni momenti)
Sega shte se opitame da nadzurnem v sushtnostta.
Tova, che potrebiteliat govori ili pishe na opredelen ezik, suvsem ne e sushtoto kato tova da polzva opredelena kodova tablitsa. Tova sa nezavisimi edno ot drugo poniatiia. Dori uchenite, koito suzdavat tezi poniatiia, oburkvat neshtata, izpolzvaiki nai-razlichni dumi za edno i sushto neshto ili narichat razlichni neshta s edno i sushto ime. Nie shte napravim plah opit da se orientirame v tozi zdrach.
Poniatiiata, koito shte definirame po-dolu, sa sporni, no po edna i li druga prichina az sum suglasen s tiah, a i shte svurshat rabota za nashiia povurhnosten pogled vurhu neshtata.
znak (character)
Abstraktsiiata znak se sustoi ot doslovna informatsiia za sushtestvuvaneto na neshto.
Naprimer: CYRILLIC CAPITAL LETTER SHORT I
“Edno “A” (ili vseki drug znak) e neshto kato platonicheski obekt: toi e ideiata za “A”, a ne samoto “A”.”
Michael E. Cohen, “Tekst i shriftove v edin mnogoezichen mezhduplatformen sviat”
url: http://www.humnet.ucla.edu/hcf/news/archive/fall1998/fontspart1.html
znakov repertoar (character repertoire)
Nabor ot znatsi. Znakoviiat repertoar ne predpolaga i ne vklyuchva v sebe si podredbata na znatsite. Toi oznachava edinstveno broia na znatsite. Razlichnite znakovi repertoari sudurzhat razlichen broi znatsi. V razlichnite znakovi repertoari mogat da sushtestvuvat edni i sushti na vunshen vid znatsi, koito da sa razlichni po svoiata logicheska sushtnost. Naprimer latinskata bukva A, kirilskata bukva A, i grutskata A (alfa) sa razlichni znatsi. Tova e vazhno da se znae, dori samo zashtoto vsichki turseshti mashini v mrezhata rabotiat v suotvetstvie s tova pravilo. Taka che, ne izpolzvaite bezrazborno naprimer latinsko e, na miastoto na kirilskiia mu ekvivalent. Mozhe da si imate problemi.
znakov kod (character code)
Kartografirane (mnogo chesto v obiknoven tekstov fail s tabulatsii), pri koeto se definirat suotvetstviia (edno kum edno) mezhdu nabor ot tseli polozhitelni chisla i znatsi ot daden znakov repertoar. Po tozi nachin vseki znak ot repertoara poluchava svoe chislo (koeto sochi kum nego), svoi chislov kod. Poluchava se tablitsa, v koiato vseki red se sustoi ot indeks (nomer) i stoinost (znak). Ne e zadulzhitelno znakoviiat kod da e sustaven ot poredni chisla. Mnogo znakovi kodove sudurzhat “dupki” — nedefinirani stoinosti. Granitsata mezhdu tova poniatie i sledvashtoto e trudno razlichima.
znakovo kodirane, kodova tablitsa (character encoding, charset)
Metod (algoritum) za predstaviane na znatsi v tsifrov format, chrez kartografirane na posledovatelnosti ot kodovi nomera na znatsi v posledovatelnosti ot okteti (osmichni chisla). V nai-prostiia sluchai vseki znak e opisan s chislo v poriaduka ot 0 do 255 (desetichni) vklyuchitelno. 2**8=256 znaka. Tazi shema raboti za nai-mnogo 256 znaka. Zatova i sme svideteli na tolkova mnogo i razlichni kodovi tablitsi. Za kodovi tablitsi, sushtoiashti se ot poveche ot 256 znaka, e neobhodim po-slozhen algoritum.
Naprimer: 0x0419 #CYRILLIC CAPITAL LETTER SHORT I
Tova e znakut, predstaven kato shestnadesetichno chislo, oboznachavasht glavnata bukva I v kirilskata azbuka v UTF-8.
Kodovite tablitsi imat imena, pod koito mogat da budat registrirani. Ofitsialniiat registur na kodovite tablitsi se poddurzha ot IANA - Internet Assigned Numbers Authority (http://iana.org).
url: http://www.iana.org/assignments/character-sets
Dokolkoto znam, tozi adres e nevaliden veche, no mozhete da poglenete i na adres: http://www.cs.tut.fi/~jkorpela/chars/sorted.html.
kontrolni znatsi (kontrolni kodove) (control characters (control codes))
Roliata na kontrolnite znatsi e malko neiasna. Te ne sa vidimi, ne se izpolzvat za pokazvane na niakakva forma vurhu ekrana. Po-skoro sluzhat za podavane na niakakuv signal. Naprimer, poiavata na opredelen znak v edin potok informatsiia mozhe da sluzhi kato signal za prekusvane na niakakuv protses.
Mozhe bi slednata izvadka ot kodova tablitsa shte vi govori neshto:
0x0017 #END OF TRANSMISSION BLOCK
ili puk
0x001B #ESCAPE
Otgore na vsichko kontrolniiat znak ESCAPE ne e logicheski svurzan s klavisha Esc, taka che i neshto drugo (osven natiskaneto mu) mozhe da izprati signala ESCAPE kum protsesora.
Druga proiava na kontrolnite znatsi sa klavishnite kombinatsii. Da vzemem CTRL+C. Tazi klavishna kombinatsiia niama nishto obshto sus znaka C. Tia prosto sluzhi za podavane na signal da se kopira neshto v klipborda.
glif (glyph)
SHTe si pozvolia da go preveda nachertanie. Glif e predstavianeto na znaka s opredelena forma, kogato biva izobrazen vurhu ekran ili renderiran po niakakuv drug nachin. Naprimer, znakut “L” mozhe da bude predstaven kato L (udebelen) ili L (italichen), no tova e vse sushtiiat znak. Znakut “l” e suvsem razlichen znak obache, koito si ima svoi glifove. Vsichko e vupros na definitsiia. Definitsiiata na edin znakov repertoar spetsifitsira unikalnostta na vseki znak v nego.
0x041B
cyrillic capital letter el
L
L
L
fig.5 Razlichni glifove
Vodiat se debati po po-natatushno razgranichavane na poniatiia kato “glif-izobrazhenie”, koeto e samoto predstaviane na znaka, i “glif”, koeto e po-abstraktno poniatie.
“An operational model for characters and glyphs”
url: http://www.iso.ch/iso/en/ittf/PubliclyAvailableStandards/C027163e.zip
shriftove (fonts)
Edin repertoar ot glifove sustavia shrift. V tehnicheski smisul, shriftut predstavliava nomeriran nabor ot glifove. Nomerata suvpadat s kodovete na znatsite. Taka shriftut e zavisim ot kodovete na znatsite i po tozi nachin se svurzva s tiah. Otnovo mozhem da utochnim, che shriftut ne e zadulzhitelno da sudurzha vsichkite kodirani pozitsii v dadena kodova tablitsa, kakto i opredelena kodova tablitsa mozhe da ne sudurzha definirani stoinosti za znak, koito puk e definiran v daden shrift chrez glif. Taka nie se sbluskvame chesto sus shriftove, koito niamat definirani glifove za kirilski bukvi i kazvame “Tozi shrift ne e kiriliziran.” Edin shrift mozhe da sudurzha samo edin ili niakolko glifa. SHriftut mozhe da ne sudurzha bukvi v smisula na poniatieto za bukvi, koeto imame v suznanieto si, no v sushtoto vreme vsichki ili pochti vsichki kodovi pozitsii da sa definirirani. Edin takuv shrift e Webdings:
shrift
fig.6 Tuk e izpisano “shrift” sus shrifta Webdings
Dobre e otnovo da se otbelezhi, che ne triabva da se izpolzvat glifove ot daden shrift samo zashtototo izglezhdat dobre. Tova vazhi za sluchaite, kogato izpolzvate naistina shrift. Ako vse pak iskate dadena forma da bude tochno edi kakva si, napravete taka, che dadenata bukva ili simvol da prestane da bude glif. Tazi tehnika se izpolzva povsemestno. Naprimer, kogato iskame da izpolzvame tochno opredelen shrift za reklamno poslanie v nashiia ueb sait, trabva da go prevurnem v niakakva bitmap-grafika (jpg, gif i t.n.), ako iskame da budem sigurni, che shte izglezhda po sushtiia nachin na vseki kompyutur. V drug sluchai, kogato iskame da podgotvim neshto za pechat, nie prevrushtame shrifta v obiknoveni krivi (vektori) i podgotviame faila za pechat. Tova obache e dalech ot nashata tema i niama da go obsuzhdame poveche.
Sled kato imame osnovnite poniatiia, mozhem da se opitame da se “gmurnem” po-dulboko.
ASCII
(American Standard Code for Information Interchange)
Amerikanski Standarten Kod za Obmiana na Informatsiia.
ASCII e oboznachenie na edin star znakov repertoar, kod i kodova tablitsa. Na vsichko tova ednovremenno.
Vsichki ili pochti vsichki suvremenni kodovi tablitsi sudurzhat v sebe si ASCII.
V dokumentatsiiata na Perl puk namerih slednata definitsiia:
“ASCII e nabor ot tseli chisla v diapazona ot 0 do 127 (desetichni), oboznachavashti interpretatsiiata na znatsi chrez displeia i drugi sistemi na kompyutrite. Poriadukut ot 0 do 127 mozhe da bude pokrit chrez ustanoviavane na bitovete(tuka ne triabva li da e baitovete?) v 7-bitovo dvoichno chislo, ottuk idva spomenavaneto na nabora kato”7-bitov ASCII”. ASCII e opisan v dokumenta na Amerikanskiia Natsionalen Institut po Standartizatsiia (ANSI-American National Standards Institute) ANSI X3.4-1986… ”
ASCII is a set of integers running from 0 to 127 (decimal) that imply character interpretation by the display and other system(s) of computers. The range 0..127 can be covered by setting the bits in a 7-bit binary digit, hence the set is sometimes referred to as a ``7-bit ASCII''. ASCII was described by the American National Standards Institute document ANSI X3.4-1986. It was also described by ISO 646:1991 (with localization for currency symbols). The full ASCII set is given in the table below as the first 128 elements. Languages that can be written adequately with the characters in ASCII include English, Hawaiian, Indonesian, Swahili and some Native American languages.
ASCII sushto spetsifitsira i kontrolni znatsi kato LF(linefeed - zarezhdane na red) i ESC, za koito stana vupros po-gore. Samiiat znakov repertoar na ASCII se sustoi ot slednite pechataemi znatsi. Purviiat znak e pauzata.
! " # $ % & ' ( ) * + , - . /
0 1 2 3 4 5 6 7 8 9 : ; ?
@ A B C D E F G H I J K L M N O
P Q R S T U V W X Y Z [ \ ] ^ _
` a b c d e f g h i j k l m n o
p q r s t u v w x y z { | } ~
Znakoviiat kod, definiran ot ASCII, e sledniiat:
Kodovite indeksi oboznachavat znatsi posledovatelno v reda, v koito sa pokazani v tablitsata gore (po redove). Zapochva se ot indeks 32, koito oboznachava prazno prostranstvo (pauza) i zavurshva s nomer 126 oboznachavasht znaka tilda (~). Pozitsiite ot 0 do 31 i pozitsiia 127 sa zapazeni za kontrolni kodove. Te imat standartizirani imena i opisaniia, no se izpolzvat za nai-razlichni neshta.
ASCII e striktno 7-bitova kodova tablitsa. Niama t.nar “8-bitov ASCII”. Vsiaka 8-bitova kodova tablitsa, sudurzhashta v sebe si ASCII, mozhe da bude razglezhdana kato negovo razshirenie. ASCII e tolkova shiroko izpolzvano poniatie, che chesto ASCII se upotrebiava kato pulen ekvivalent na tekst. Naprimer, ASCII fail bi triabvalo da oznachava tekstov fail kato obratnoto na dvoichen fail.
8-bitovi kodovi tablitsi
iso 8859-1
Standartut ISO 8859-1 definira znakov repertoar, poznat kato latinska azbuka №1. Nai-chesto se upotrebiava poniatieto "ISO Latin 1" Repertoarut mu sudurzha ASCII v sebe si kato podmnozhestvo i indeksite na ASCII-znatsite sa sushtite. Standartut spetsifitsira kodirane, podobno na ASCII. Vsichki znatsi sa predstaveni kato osmichni chisla. V dopulnenie kum ASCII-znatsite ISO Latin 1 sudurzha nai-razlichni znatsi s udareniia, davashti vuzmozhnost da se pishe na ezitsite ot Zapadna Evropa. ISO Latin 1 ne sudurzha znaka ? naprimer, izpolzvan vuv frenski ezik, kakto i niakoi drugi simvoli. Eto tablitsa sus znatsite ot ISO Latin 1 (pozitsii ot 160 do 255).
? ? ? ¤ ? ¦ § ? © ? « ¬ ® ?
° ± ? ? ? µ ¶ · ? ? ? » ? ? ? ?
A A A A A A ? C E E E E I I I I
? N O O O O O ? O U U U U Y ? ?
a a a a a a ? c e e e e i i i i
? n o o o o o ? o u u u u y ? y
Znatsite s nomera ot 128 do 159 sa iztsialo s kontrolni funktsii i v tiah niama pechataemi znatsi. Znak 160 e t.nar no-break space, a znak 173 e poznat kato meko tire (soft-hyphen). To e vidimo samo kogato prisustva na opredeleno miasto v dadena duma i tia se namira v kraia na reda. Togava dumata se “razdelia” v dva posledovatelni reda i mekoto tire stava vidimo. Mnogo e udobno za tekst, koito teche i ne mozhe da se opredeli konkretno shirinata na stranitsata. V dumite se postaviat meki tireta, koito se poiaviavat v sluchai, che dadena duma triabva da se prenese na sledvashtiia red. Pochti mi izbiaga bulgarskata dumichka — srichkoprenasiane.
Triabva da spomenem, che e vazhno da ne se burka tazi kodova tablitsa s t.nar. Windows Western ili kakto oshte e izvestna Windows-1252. Tia mnogo prilicha na ISO-8859-1, s tazi razlika, che v neia prisustvat i pechataemi znatsi v poriaduka ot znak 128 do 159. Naprimer znak 128 e znakut za evro-valuta (€), znak 156 ni dava frenskata ligatura ? i t.n. Kak da izpolzvame tezi znatsi, shte razberem malko po-natatuk.
windows-1251*
*V dokumentatsiiata na survura za bazi danni MySQL se pravi razlika mezhdu CP1251 i WINDOWS-1251. V sluchaite v koito sum izpolzval dvete formulirovki, kato vzamozameniaemi ne sum imal problemi.
Nai-izpolzvanata kodova tablitsa v Bulgariia e WINDOWS-1251.
Dori i da ne znaehte dosega, vie ia polzvate ezhednevno, osobeno ako rabotite s niakoia ot versiite na OS Windows 9X. V diska kum spisanieto, v direktoriia tools (Pesho, shte kazhesh koia papka - tools mozhe bi), razopakovaite faila cp1251.zip i shte namerite edin dosta podroben HTML-dokument (CP1251.htm), kudeto v tablichna forma sa predstaveni kodovete na znatsite i samite znatsi ot WINDOWS-1251, kakto i kodovete im sled konversiia v Unicode. Tam sum postavil i izhodniia tekstov fail, kakto i skripta, koito napisah, za da generiram HTML-tablitsata. Nadiavam se tablitsata da vi bude polezna.
Internatsionalizatsiia
Globalizatsiiata e neizbezhna… h-m. Edno ot neinite sredstva e unifitsirane na standartite. 8-bitovite kodovi tablitsi ne mogat da pomognat. Ochevidno e neobhodimo generalno reshenie na tozi problem. Unicode Consortium (http://www.unicode.org) e organizatsiia, koiato se e zaela s izrabotvaneto na shema, po koiato v edna kodova tablitsa da se suberat vsichki znatsi, poznati do sega na planetata Zemia. Kolko ambitsiozno!..
Tuk naimenovaniiata, poniatiiata i algoritmite sa do takava stepen prepleteni, che e trudno da se kazhe koe kakvo e. Eto chast ot informatsiiata, koiato otkrih po vuprosa.
iso 10646
Ofitsialno: (ISO/IEC 10646) e mezhdunaroden standart na ISO i IEC(International Electrotechnical Commission). Toi definira UCS(Universal Character Set) — Universalna Kodova Tablitsa, s ogromen i postoianno narastvasht znakov repertoar i znakov kod za nego. Veche sa definirani nad 40 000 znaka.
unicode
Tova e standart ot Unicode Consortium, koito definira znakov kod i znakov repertoar, napulno suvmestim s ISO 10646, a sushto i kodova tablitsa za nego. ISO 10646 e po-abstrakten po priroda, dokato Unicode nalaga dopulnitelni ogranicheniia otnosno implementatsiiata i prenosimostta mezhdu razlichni platformi i prilozheniia. Podrobnosti po tozi vupros mozhete da otkriete v Unicode FAQ (http://www.unicode.org/unicode/faq/). ISO 10646 i Unicode mogat da budat razglezhdani kato nadstroika na povecheto 8-bitovi kodovi tablitsi. Estestveno, kodovete na znatsite ne suvpadat, osven purvite 127.
Na praktika pochti nikoi ne govori za ISO 10646. Vsichki govoriat za Unicode. Ima razliki mezhdu dvata standarta, no te sa opisani tolkova podrobno, che trudno se razbira osnovnata ideia. Poslednata versiia (po vreme na pisaneto na statiiata) na Unicode e 3.2. Hubavo e pone, che definiranite do sega znatsi ne promeniat podredbata si, a samo se dobaviat novi.
Vse pak triabvashe da se hvana za neshto i trugnah ot ochevidnoto. Po menyutata na raznite prilozheniia, koito mogat da polzvat razlichni kodovi tablitsi, navsiakude pisheshe Unicode i Unicode(UTF-8). Zapochnah da eksperimentiram. Da si priznaia, tova izglezhda e nai-sigurniiat nachin da razberesh neshto kak raboti. Mozhe da ne si prochel edna duma po vuprosa, no go poznavash, zashtototo znaesh kak se durzhi.
Reshih da generiram znatsite ot 0 do 50 000. Imashe definiran znak s poreden nomer 50 000, makar da go vizhdah kato kvadratche. Ili imashe kontrolni funktsii, ili lipsvashe shrift, koito da go predstavi.
UCS (ili Unicode!?) sudurzha v svoia repertoar vsichki znatsi ot kodovite tablitsi, obsudeni dotuk.
utf-8 (Unicode Transformation Format-8) i drugi algoritmi
UCS i Unicode sa prosto kartografirani chrez tseli chisla znakovi repertoari. Kogato kazhem UCS, ISO 10646 ili Unicode, oznachava prosto ideiata za obvurzvane na znatsi s chisla, na indeksi sus stoinosti. Tova ne dava predstava kak shte se zapisvat tezi chisla kato posledovatelnost ot baitove v pametta na kompyutura. Ima nai-razlichni nachini. Okazva se naprimer, che HTML 4.0 se razglezhda kato otdelen takuv metod. Izpisva se kato referentsiia poredniia nomer na znaka i HTML-parserut na suotvetniia brauzur generira (izvikva) znaka vurhu ekrana.
Eto taka:
V koda izpisvame ©, a na ekrana vizhdame ©.
Tova e razlichno ot izpolzvaneto na meta taga
http-equiv="Content-Type" content="text/html;
charset=utf-8">, koito ukazva na brauzura koia kodova tablitsa da polzva, za da renderira dokumenta.
Ako vashiiat tekstov redaktor pozvoliava vuvezhdane na simvoli chrez klavishni kombinatsii i vashiiat HTML dokument e kodiran v UTF-8, to vie shte imate znaka © v samiia kod. Niama znachenie kakva kodova tablitsa polzva HTML dokumenta, ako napishete © v brauzura shte vidite ©, dori ako znakoviiat repertoar na polzvanata kodova tablitsa ne sudurzha tozi znak. JAVA (ezikut za programirane) si ima svoi nachin. Polzva UTF-16 “vutreshno”. UTF-8 e samo edin ot poddurzhanite algoritmi.
Oshte ne sme razbrali kakvo e UTF-8. Okazva se, che tova e samo edin ot nachinite, po koito mozhe da se predstavia Unicode v baitovi posledovatelnosti.
Eto niakoi ot harakteristikite mu:
- UCS znatsite ot 0000 do 007F(shestnadesetichni) (0 do127 — desetichni) sa kodirani kato baitove 0x0000 do 0x007F, kakto pri ASCII. Tova oznachava, che failove sus 7 bitovi znatsi, kodirani v ASCII, sa kodirani po sushtiia nachin i znatsite shte budat procheteni po sushtiia nachin.
- Vsichki sledvashti znatsi, po-golemi ot 0x007F, sa kodirani kato posledovatelnost ot niakolko baita, kato e ustanoven nai-starshiiat bit. Sledovatelno nikoi ASCII znak niama da bude oburkan s ne-ASCII.
- UTF-8 teoretichno mozhe da predstavia znatsi s golemina do 6 baita, no edva li skoro shte vidim takova chudo. Nie sme sviknali edin simvol da e edin bait. Ponastoiashtem sushtestvuvat znatsi s golemina nai-mnogo 3 baita.
- V mrezhata mozhete da namerite mnogo podrobna informatsiia. Nie shte se zadovolim s tova da znaem, che veche niamame problemi s polzvaneto na kirilitsa.
Ako se interesuvate kak da suzdavate UTF-8 kodirani dokumenti, prochetete help-failovete na prilozheniiata, s koito rabotite. Napulno e vuzmozhno da ne namerite mnogo po vuprosa. Sushtestvuvat obache t.nar Unicode redaktori kato bezplatniiat Yudit (http://www.yudit.org ), Unipad i dr. Naposleduk vse poveche redaktori za ueb-programirane, predlagat poddruzhka na UTF-8 moite lyubimi redaktori sa QUANTA i “AceHTML Freeware”.
Sigurno znaete sushto, che vsiako KDE prilozhenie poddurzha UNIKOD.



 Variant za otpechatvane
Variant za otpechatvane