Извинявам се за несъответствията в показаните знаци.
Ще се погрижа да редактирам статията и там, където има несъответствия ще поставя картинки, за да съм сигурен, че ще видите, това, което трябва да видите
Референтни връзки към статията:
http://berov.data.bg/Cyr_and_charsets/tools/README.htm
Забележка:
!!! Тези документи няма да се заредят правилно, защото сървърът (data.bg) изпраща хедър charset=windows-1251, а документите са кодирани в utf-8.
За да ги видите както трябва в браузъра си, използвайте менюто View>Encoding>utf-8
[НИКОГА НЕ ПУБЛИКУВАНА СТАТИЯ]
Работно заглавие:
Кирилицата и кодовите таблици
(използване на различни кодови таблици в Интернет)
Красимир Беров
Увод
За потребители
(как да четем и изпращаме електронната си поща, използвайки кирилица)
Голяма част от нас — потребителите имат пощенски кутии на някой от безплатните пощенски сървъри по света. От няколко години насам се появиха и много български сървъри, обслужващи потребителски пощенски кутии — платени и безплатни. Макар и запознати с факта, че може да се ползва кирилица, много от нас продъжават да ползват “по-сигурната” “интернетица”, както я беше нарекъл Мартин Карбовски в една своя статия. За съжаление от нея не ставаше ясно защо се случва така. Е, по-нататък ще обясним, а сега само ще покажем как да ползваме системата от символи на Светите Братя и ученика им св. Климент Охридски.
Целият проблем се корени във факта, че почти всяка страна, използваща символите на св. Климент Охридски (защото той създава кирилицата), има своя система за представяне на тези знаци върху стандартния изход — екрана. Освен самите вътредържавни органи по стандартизация има и външни фактори като MICROSOFT CORPORATION, W3C-World Wide Web Consortium, ISO-International Standards Organization, Unicode Consortium, които предлагат свои системи и налагат използването на определени схеми за трансформиране на числа в символи върху екрана.
Нас — крайните потребители не ни интересува нищо от това, до момента, в който не отворим някой документ в MS Word (или просто в пощенската си кутия в браузъра) и се окаже, че той е изпъстрен с квадратчета или странни букви с ударения.
Ето най-използваните т.нар кодови таблици за представяне на кирилски символи.
- windows-1251 или cp1251
- koi-8r
- koi-8u
- cp866
- iso-8859-5
- utf-8
За да използвате кирилица, когато изпращате или получавате електронна поща:
А: Internet Explorer
Ако не сте настроили браузъра си предварително да приема определени кодови таблици или пък очаквате писмо кодирано с определена кодова таблица, от менюто View изберете Encoding и от там изберете кодовата таблица, която евентуално е използвана.
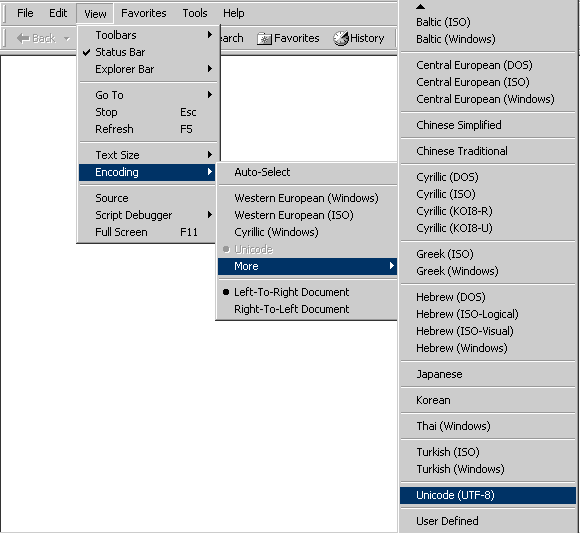
фиг.1 Използване на различни кодови таблици в Internet Explorer
Б: Mozilla 1/Netscape 6 и следващи версии
Тук менютата са подобни.
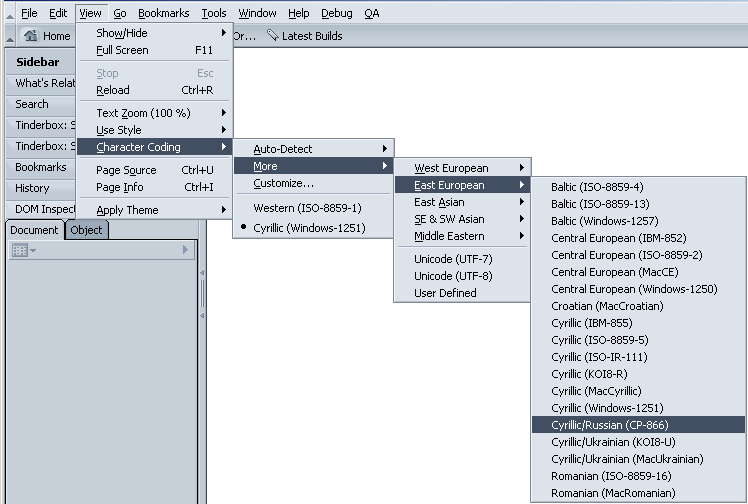 фиг.2 Използване на различни кодови таблици в Mozilla /Netscape
фиг.2 Използване на различни кодови таблици в Mozilla /Netscape
Тези умения можеше и да не са ви необходими, ако сайтът, хостващ вашата пощенска кутия, разпознаваше езика и кодовата таблица, която ползва вашият браузър по подразбиране. Малко сайтове в мрежата се грижат за това. Един от тях е http://www.google.com. Той се зарежда направо на кирилица и можете да търсите, използвайки български букви. И кирилицата не е нищо. Какво ще кажете за японските или китайските идеографии? Оставате впечатлени, нали?
Когато решите да си пишете с някой приятел, заминал в чужбина, просто се уговорете коя кодова таблица ще ползвате. Така няма да имате проблеми с кирилицата. Изберете си някакъв поддържан от неговата и от вашата операционна система шрифт, и сте готови.
В случай, че сте от хората, които обичат да си плащат, вие най-вероятно имате пощенска кутия на някой от платените сървъри и ползвате програма като Outlook Express. По принцип настройките за ползваната кодова таблица от вашата операционна система са направени още по време на нейното инсталиране. Тези настройки се наследяват от повечето приложения, работещи на компютъра ви в последствие. Когато работите под Windows, системата не ви дава особени обяснения за кодовата таблица, която ще ползва. Тя сама решава, че например щом се намирате в България ще ползвате windows-1251. Незнайно защо обаче Outlook Express решава да ползва koi-8r по подразбиране.
Вижте как можете да изпратите писмо (Rich Text-HTML), използващо определена кодова таблица.
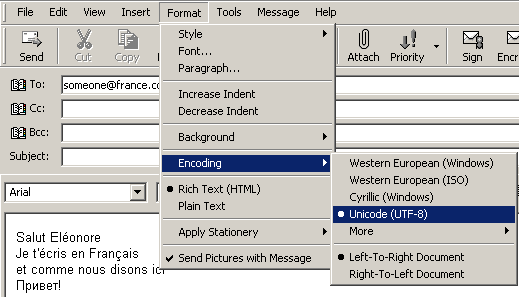
фиг.3 Използване на utf-8 в Outlook Express
Виждате, че не просто е възможно да ползвате кирилица, но е възможно да ползвате вякакви езици в един и същ документ. Как се случва това, ще обясним по-нататък.
И отново ще дам пример с използване на най-лансираната международна кодова таблица, този път с Mozilla Composer. Предварително се извинявам на владеещите Японски език. Единственото, което знам за въведените от мен символи, е че са Kanji, каквото и да означава това. Разбира се, за да можете да възпроизведете тези знаци ви е необходим шрифт, който да ги съдържа в себе си.

фиг.4 Използване на utf-8 в Mozilla Composer
Mozilla по принцип дава малко повече информация на потребителите за имената на кодовите таблици.
Като потребители, които искат просто да си свършат работа, наистина нямате нужда от повече. Но дори ако ви е само любопитно, как работят тези абстрактни схеми, преминете към следващата част.
Знаци, кодови таблици, репертоари, шрифтове
(основни моменти)
Сега ще се опитаме да надзърнем в същността.
Това, че потребителят говори или пише на определен език, съвсем не е същото като това да ползва определена кодова таблица. Това са независими едно от друго понятия. Дори учените, които създават тези понятия, объркват нещата, използвайки най-различни думи за едно и също нещо или наричат различни неща с едно и също име. Ние ще направим плах опит да се ориентираме в този здрач.
Понятията, които ще дефинираме по-долу, са спорни, но по една и ли друга причина аз съм съгласен с тях, а и ще свършат работа за нашия повърхностен поглед върху нещата.
знак (character)
Абстракцията знак се състои от дословна информация за съществуването на нещо.
Например: CYRILLIC CAPITAL LETTER SHORT I
“Едно “А” (или всеки друг знак) е нещо като платонически обект: той е идеята за “А”, а не самото “А”.”
Michael E. Cohen, “Текст и шрифтове в един многоезичен междуплатформен свят”
url: http://www.humnet.ucla.edu/hcf/news/archive/fall1998/fontspart1.html
знаков репертоар (character repertoire)
Набор от знаци. Знаковият репертоар не предполага и не включва в себе си подредбата на знаците. Той означава единствено броя на знаците. Различните знакови репертоари съдържат различен брой знаци. В различните знакови репертоари могат да съществуват едни и същи на външен вид знаци, които да са различни по своята логическа същност. Например латинската буква А, кирилската буква А, и гръцката А (алфа) са различни знаци. Това е важно да се знае, дори само защото всички търсещи машини в мрежата работят в съответствие с това правило. Така че, не използвайте безразборно например латинско е, на мястото на кирилския му еквивалент. Може да си имате проблеми.
знаков код (character code)
Картографиране (много често в обикновен текстов файл с табулации), при което се дефинират съответствия (едно към едно) между набор от цели положителни числа и знаци от даден знаков репертоар. По този начин всеки знак от репертоара получава свое число (което сочи към него), свой числов код. Получава се таблица, в която всеки ред се състои от индекс (номер) и стойност (знак). Не е задължително знаковият код да е съставен от поредни числа. Много знакови кодове съдържат “дупки” — недефинирани стойности. Границата между това понятие и следващото е трудно различима.
знаково кодиране, кодова таблица (character encoding, charset)
Метод (алгоритъм) за представяне на знаци в цифров формат, чрез картографиране на последователности от кодови номера на знаци в последователности от октети (осмични числа). В най-простия случай всеки знак е описан с число в порядъка от 0 до 255 (десетични) включително. 2**8=256 знака. Тази схема работи за най-много 256 знака. Затова и сме свидетели на толкова много и различни кодови таблици. За кодови таблици, същоящи се от повече от 256 знака, е необходим по-сложен алгоритъм.
Например: 0x0419 #CYRILLIC CAPITAL LETTER SHORT I
Това е знакът, представен като шестнадесетично число, обозначаващ главната буква Й в кирилската азбука в UTF-8.
Кодовите таблици имат имена, под които могат да бъдат регистрирани. Официалният регистър на кодовите таблици се поддържа от IANA - Internet Assigned Numbers Authority (http://iana.org).
url: http://www.iana.org/assignments/character-sets
Доколкото знам, този адрес е невалиден вече, но можете да погленете и на адрес: http://www.cs.tut.fi/~jkorpela/chars/sorted.html.
контролни знаци (контролни кодове) (control characters (control codes))
Ролята на контролните знаци е малко неясна. Те не са видими, не се използват за показване на някаква форма върху екрана. По-скоро служат за подаване на някакъв сигнал. Например, появата на определен знак в един поток информация може да служи като сигнал за прекъсване на някакъв процес.
Може би следната извадка от кодова таблица ще ви говори нещо:
0x0017 #END OF TRANSMISSION BLOCK
или пък
0x001B #ESCAPE
Отгоре на всичко контролният знак ESCAPE не е логически свързан с клавиша Esc, така че и нещо друго (освен натискането му) може да изпрати сигнала ESCAPE към процесора.
Друга проява на контролните знаци са клавишните комбинации. Да вземем CTRL+C. Тази клавишна комбинация няма нищо общо със знака C. Тя просто служи за подаване на сигнал да се копира нещо в клипборда.
глиф (glyph)
Ще си позволя да го преведа начертание. Глиф е представянето на знака с определена форма, когато бива изобразен върху екран или рендериран по някакъв друг начин. Например, знакът “Л” може да бъде представен като Л (удебелен) или Л (италичен), но това е все същият знак. Знакът “л” е съвсем различен знак обаче, който си има свои глифове. Всичко е въпрос на дефиниция. Дефиницията на един знаков репертоар специфицира уникалността на всеки знак в него.
0x041B
cyrillic capital letter el
Л
Л
Л
фиг.5 Различни глифове
Водят се дебати по по-нататъшно разграничаване на понятия като “глиф-изображение”, което е самото представяне на знака, и “глиф”, което е по-абстрактно понятие.
“An operational model for characters and glyphs”
url: http://www.iso.ch/iso/en/ittf/PubliclyAvailableStandards/C027163e.zip
шрифтове (fonts)
Един репертоар от глифове съставя шрифт. В технически смисъл, шрифтът представлява номериран набор от глифове. Номерата съвпадат с кодовете на знаците. Така шрифтът е зависим от кодовете на знаците и по този начин се свързва с тях. Отново можем да уточним, че шрифтът не е задължително да съдържа всичките кодирани позиции в дадена кодова таблица, както и определена кодова таблица може да не съдържа дефинирани стойности за знак, който пък е дефиниран в даден шрифт чрез глиф. Така ние се сблъскваме често със шрифтове, които нямат дефинирани глифове за кирилски букви и казваме “Този шрифт не е кирилизиран.” Един шрифт може да съдържа само един или няколко глифа. Шрифтът може да не съдържа букви в смисъла на понятието за букви, което имаме в съзнанието си, но в същото време всички или почти всички кодови позиции да са дефинирирани. Един такъв шрифт е Webdings:
шрифт
фиг.6 Тук е изписано “шрифт” със шрифта Webdings
Добре е отново да се отбележи, че не трябва да се използват глифове от даден шрифт само защотото изглеждат добре. Това важи за случаите, когато използвате наистина шрифт. Ако все пак искате дадена форма да бъде точно еди каква си, направете така, че дадената буква или символ да престане да бъде глиф. Тази техника се използва повсеместно. Например, когато искаме да използваме точно определен шрифт за рекламно послание в нашия уеб сайт, трабва да го превърнем в някаква битмап-графика (jpg, gif и т.н.), ако искаме да бъдем сигурни, че ще изглежда по същия начин на всеки компютър. В друг случай, когато искаме да подготвим нещо за печат, ние превръщаме шрифта в обикновени криви (вектори) и подготвяме файла за печат. Това обаче е далеч от нашата тема и няма да го обсъждаме повече.
След като имаме основните понятия, можем да се опитаме да се “гмурнем” по-дълбоко.
ASCII
(American Standard Code for Information Interchange)
Американски Стандартен Код за Обмяна на Информация.
ASCII е обозначение на един стар знаков репертоар, код и кодова таблица. На всичко това едновременно.
Всички или почти всички съвременни кодови таблици съдържат в себе си ASCII.
В документацията на Perl пък намерих следната дефиниция:
“ASCII е набор от цели числа в диапазона от 0 до 127 (десетични), обозначаващи интерпретацията на знаци чрез дисплея и други системи на компютрите. Порядъкът от 0 до 127 може да бъде покрит чрез установяване на битовете(тука не трябва ли да е байтовете?) в 7-битово двоично число, оттук идва споменаването на набора като”7-битов ASCII”. ASCII е описан в документа на Американския Национален Институт по Стандартизация (ANSI-American National Standards Institute) ANSI X3.4-1986… ”
ASCII is a set of integers running from 0 to 127 (decimal) that imply character interpretation by the display and other system(s) of computers. The range 0..127 can be covered by setting the bits in a 7-bit binary digit, hence the set is sometimes referred to as a ``7-bit ASCII''. ASCII was described by the American National Standards Institute document ANSI X3.4-1986. It was also described by ISO 646:1991 (with localization for currency symbols). The full ASCII set is given in the table below as the first 128 elements. Languages that can be written adequately with the characters in ASCII include English, Hawaiian, Indonesian, Swahili and some Native American languages.
ASCII също специфицира и контролни знаци като LF(linefeed - зареждане на ред) и ESC, за който стана въпрос по-горе. Самият знаков репертоар на ASCII се състои от следните печатаеми знаци. Първият знак е паузата.
! " # $ % & ' ( ) * + , - . /
0 1 2 3 4 5 6 7 8 9 : ; ?
@ A B C D E F G H I J K L M N O
P Q R S T U V W X Y Z [ \ ] ^ _
` a b c d e f g h i j k l m n o
p q r s t u v w x y z { | } ~
Знаковият код, дефиниран от ASCII, е следният:
Кодовите индекси обозначават знаци последователно в реда, в който са показани в таблицата горе (по редове). Започва се от индекс 32, който обозначава празно пространство (пауза) и завършва с номер 126 обозначаващ знака тилда (~). Позициите от 0 до 31 и позиция 127 са запазени за контролни кодове. Те имат стандартизирани имена и описания, но се използват за най-различни неща.
ASCII е стриктно 7-битова кодова таблица. Няма т.нар “8-битов ASCII”. Всяка 8-битова кодова таблица, съдържаща в себе си ASCII, може да бъде разглеждана като негово разширение. ASCII е толкова широко използвано понятие, че често ASCII се употребява като пълен еквивалент на текст. Например, ASCII файл би трябвало да означава текстов файл като обратното на двоичен файл.
8-битови кодови таблици
iso 8859-1
Стандартът ISO 8859-1 дефинира знаков репертоар, познат като латинска азбука №1. Най-често се употребява понятието "ISO Latin 1" Репертоарът му съдържа ASCII в себе си като подмножество и индексите на ASCII-знаците са същите. Стандартът специфицира кодиране, подобно на ASCII. Всички знаци са представени като осмични числа. В допълнение към ASCII-знаците ISO Latin 1 съдържа най-различни знаци с ударения, даващи възможност да се пише на езиците от Западна Европа. ISO Latin 1 не съдържа знака ? например, използван във френски език, както и някои други символи. Ето таблица със знаците от ISO Latin 1 (позиции от 160 до 255).
? ? ? ¤ ? ¦ § ? © ? « ¬ ® ?
° ± ? ? ? µ ¶ · ? ? ? » ? ? ? ?
A A A A A A ? C E E E E I I I I
? N O O O O O ? O U U U U Y ? ?
a a a a a a ? c e e e e i i i i
? n o o o o o ? o u u u u y ? y
Знаците с номера от 128 до 159 са изцяло с контролни функции и в тях няма печатаеми знаци. Знак 160 е т.нар no-break space, а знак 173 е познат като меко тире (soft-hyphen). То е видимо само когато присъства на определено място в дадена дума и тя се намира в края на реда. Тогава думата се “разделя” в два последователни реда и мекото тире става видимо. Много е удобно за текст, който тече и не може да се определи конкретно ширината на страницата. В думите се поставят меки тирета, които се появяват в случай, че дадена дума трябва да се пренесе на следващия ред. Почти ми избяга българската думичка — сричкопренасяне.
Трябва да споменем, че е важно да не се бърка тази кодова таблица с т.нар. Windows Western или както още е известна Windows-1252. Тя много прилича на ISO-8859-1, с тази разлика, че в нея присъстват и печатаеми знаци в порядъка от знак 128 до 159. Например знак 128 е знакът за евро-валута (€), знак 156 ни дава френската лигатура ? и т.н. Как да използваме тези знаци, ще разберем малко по-нататък.
windows-1251*
*В документацията на сървъра за бази данни MySQL се прави разлика между CP1251 и WINDOWS-1251. В случаите в които съм използвал двете формулировки, като взамозаменяеми не съм имал проблеми.
Най-използваната кодова таблица в България е WINDOWS-1251.
Дори и да не знаехте досега, вие я ползвате ежедневно, особено ако работите с някоя от версиите на OS Windows 9X. В диска към списанието, в директория tools (Пешо, ще кажеш коя папка - tools може би), разопаковайте файла cp1251.zip и ще намерите един доста подробен HTML-документ (CP1251.htm), където в таблична форма са представени кодовете на знаците и самите знаци от WINDOWS-1251, както и кодовете им след конверсия в Unicode. Там съм поставил и изходния текстов файл, както и скрипта, който написах, за да генерирам HTML-таблицата. Надявам се таблицата да ви бъде полезна.
Интернационализация
Глобализацията е неизбежна… х-м. Едно от нейните средства е унифициране на стандартите. 8-битовите кодови таблици не могат да помогнат. Очевидно е необходимо генерално решение на този проблем. Unicode Consortium (http://www.unicode.org) е организация, която се е заела с изработването на схема, по която в една кодова таблица да се съберат всички знаци, познати до сега на планетата Земя. Колко амбициозно!..
Тук наименованията, понятията и алгоритмите са до такава степен преплетени, че е трудно да се каже кое какво е. Ето част от информацията, която открих по въпроса.
iso 10646
Официално: (ISO/IEC 10646) е международен стандарт на ISO и IEC(International Electrotechnical Commission). Той дефинира UCS(Universal Character Set) — Универсална Кодова Таблица, с огромен и постоянно нарастващ знаков репертоар и знаков код за него. Вече са дефинирани над 40 000 знака.
unicode
Това е стандарт от Unicode Consortium, който дефинира знаков код и знаков репертоар, напълно съвместим с ISO 10646, а също и кодова таблица за него. ISO 10646 е по-абстрактен по природа, докато Unicode налага допълнителни ограничения относно имплементацията и преносимостта между различни платформи и приложения. Подробности по този въпрос можете да откриете в Unicode FAQ (http://www.unicode.org/unicode/faq/). ISO 10646 и Unicode могат да бъдат разглеждани като надстройка на повечето 8-битови кодови таблици. Естествено, кодовете на знаците не съвпадат, освен първите 127.
На практика почти никой не говори за ISO 10646. Всички говорят за Unicode. Има разлики между двата стандарта, но те са описани толкова подробно, че трудно се разбира основната идея. Последната версия (по време на писането на статията) на Unicode е 3.2. Хубаво е поне, че дефинираните до сега знаци не променят подредбата си, а само се добавят нови.
Все пак трябваше да се хвана за нещо и тръгнах от очевидното. По менютата на разните приложения, които могат да ползват различни кодови таблици, навсякъде пишеше Unicode и Unicode(UTF-8). Започнах да експериментирам. Да си призная, това изглежда е най-сигурният начин да разбереш нещо как работи. Може да не си прочел една дума по въпроса, но го познаваш, защотото знаеш как се държи.
Реших да генерирам знаците от 0 до 50 000. Имаше дефиниран знак с пореден номер 50 000, макар да го виждах като квадратче. Или имаше контролни функции, или липсваше шрифт, който да го представи.
UCS (или Unicode!?) съдържа в своя репертоар всички знаци от кодовите таблици, обсъдени дотук.
utf-8 (Unicode Transformation Format-8) и други алгоритми
UCS и Unicode са просто картографирани чрез цели числа знакови репертоари. Когато кажем UCS, ISO 10646 или Unicode, означава просто идеята за обвързване на знаци с числа, на индекси със стойности. Това не дава представа как ще се записват тези числа като последователност от байтове в паметта на компютъра. Има най-различни начини. Оказва се например, че HTML 4.0 се разглежда като отделен такъв метод. Изписва се като референция поредния номер на знака и HTML-парсерът на съответния браузър генерира (извиква) знака върху екрана.
Ето така:
В кода изписваме ©, а на екрана виждаме ©.
Това е различнo от използването на мета тага
http-equiv="Content-Type" content="text/html;
charset=utf-8">, който указва на браузъра коя кодова таблица да ползва, за да рендерира документа.
Ако вашият текстов редактор позволява въвеждане на символи чрез клавишни комбинации и вашият HTML документ е кодиран в UTF-8, то вие ще имате знака © в самия код. Няма значение каква кодова таблица ползва HTML документа, ако напишете © в браузъра ще видите ©, дори ако знаковият репертоар на ползваната кодова таблица не съдържа този знак. JAVA (езикът за програмиране) си има свой начин. Ползва UTF-16 “вътрешно”. UTF-8 е само един от поддържаните алгоритми.
Още не сме разбрали какво е UTF-8. Оказва се, че това е само един от начините, по които може да се представя Unicode в байтови последователности.
Ето някои от характеристиките му:
- UCS знаците от 0000 до 007F(шестнадесетични) (0 до127 — десетични) са кодирани като байтове 0x0000 до 0x007F, както при ASCII. Това означава, че файлове със 7 битови знаци, кодирани в ASCII, са кодирани по същия начин и знаците ще бъдат прочетени по същия начин.
- Всички следващи знаци, по-големи от 0x007F, са кодирани като последователност от няколко байта, като е установен най-старшият бит. Следователно никой ASCII знак няма да бъде объркан с не-ASCII.
- UTF-8 теоретично може да представя знаци с големина до 6 байта, но едва ли скоро ще видим такова чудо. Ние сме свикнали един символ да е един байт. Понастоящем съществуват знаци с големина най-много 3 байта.
- В мрежата можете да намерите много подробна информация. Ние ще се задоволим с това да знаем, че вече нямаме проблеми с ползването на кирилица.
Ако се интересувате как да създавате UTF-8 кодирани документи, прочетете help-файловете на приложенията, с които работите. Напълно е възможно да не намерите много по въпроса. Съществуват обаче т.нар Unicode редактори като безплатният Yudit (http://www.yudit.org ), Unipad и др. Напоследък все повече редактори за уеб-програмиране, предлагат поддръжка на UTF-8 моите любими редактори са QUANTA и “AceHTML Freeware”.
Сигурно знаете също, че всяко KDE приложение поддържа УНИКОД.



 Вариант за отпечатване
Вариант за отпечатване